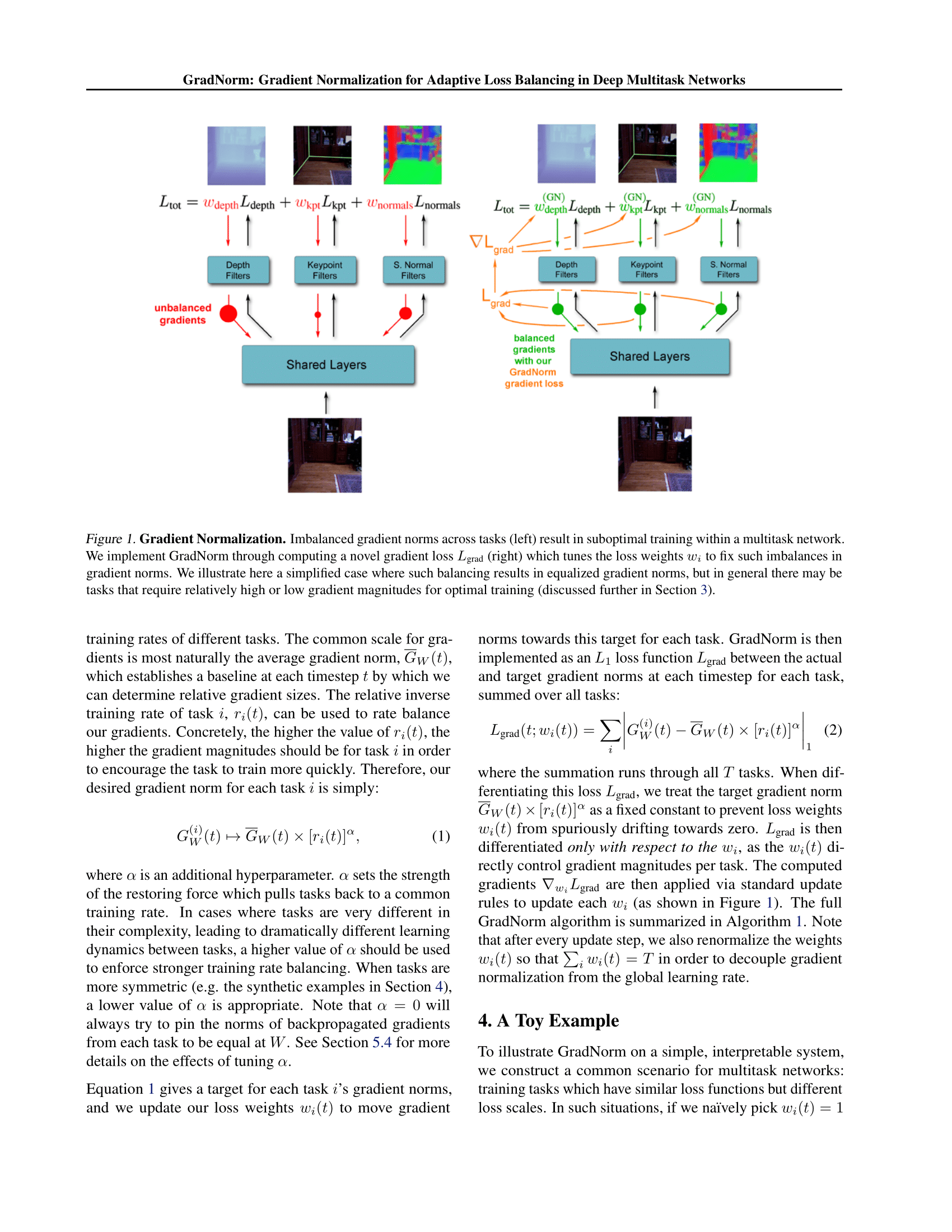
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
| class GradNormLossesModel(tf.keras.Model):
def __init__(self, alpha=0.5, layer_name='gradnorm', *args, **kwargs):
super().__init__(*args, **kwargs)
self.layer_name = layer_name
self.alpha = alpha
self.L0 = [tf.Variable(np.log(2), trainable=False, dtype=tf.float32) for _ in range(len(self.output_names))]
self.loss_ws = [tf.Variable(1.0, trainable=True, constraint=tf.keras.constraints.NonNeg(), name=str(i) + '_loss_ws')
for i in range(len(self.output_names))]
lr_schedule_ws = tf.keras.optimizers.schedules.ExponentialDecay(
initial_learning_rate=1e-2,
decay_steps=100,
decay_rate=0.75)
self.optimizer_ws = tf.keras.optimizers.Adam(learning_rate=lr_schedule_ws)
def train_step(self, data):
x, y = data
with tf.GradientTape(persistent=True) as tape:
y_pred = self(x, training=True)
losses_value = []
weighted_losses = []
total_loss = 0.0
for i in range(len(self.output_names)):
target_name = self.output_names[i]
Li = self.loss[target_name](y_true=y[target_name], y_pred=y_pred[i])
losses_value.append(Li)
w_Li = tf.multiply(self.loss_ws[i], Li)
weighted_losses.append(w_Li)
total_loss = tf.add(total_loss, w_Li)
loss_rate = tf.stack(losses_value, axis=0) / tf.stack(self.L0, axis=0)
loss_rate_mean = tf.reduce_mean(loss_rate)
loss_r = loss_rate / loss_rate_mean
last_shared_layer_var = [l for l in self.trainable_variables if 'level_1_expert_shared' in l.name]
grads = [tape.gradient(wLi, last_shared_layer_var) for wLi in weighted_losses]
grads_mid = [tf.concat([tf.reshape(g, (-1, 1)) for g in gs], axis=0) for gs in grads]
gnorms_mid = [(tf.reduce_sum(tf.multiply(g, g))) ** self.alpha for g in grads_mid]
gnorms = tf.stack(gnorms_mid, axis=0)
avgnorm = tf.reduce_mean(gnorms)
grad_diff = tf.abs(gnorms - tf.stop_gradient(avgnorm * (loss_r ** self.alpha)))
gnorm_loss = tf.reduce_sum(grad_diff)
trainable_vars = [var for var in self.trainable_variables if '_loss_ws' not in var.name]
gradients = tape.gradient(total_loss, trainable_vars)
self.optimizer.apply_gradients(zip(gradients, trainable_vars))
gradws = tape.gradient(gnorm_loss, self.loss_ws)
self.optimizer_ws.apply_gradients(zip(gradws, self.loss_ws))
factor = tf.divide(tf.constant(len(self.output_names), dtype=tf.float32), tf.reduce_sum(self.loss_ws))
for i in range(len(self.output_names)):
self.loss_ws[i].assign(tf.multiply(factor, self.loss_ws[i]))
self.compiled_metrics.update_state(y, y_pred)
del tape
return {m.name: m.result() for m in self.metrics}
|