Multi-Task Learning Using Uncertainty to Weigh Losses for Scene Geometry and Semantics
本文最后更新于:2022年11月29日 下午
论文解读
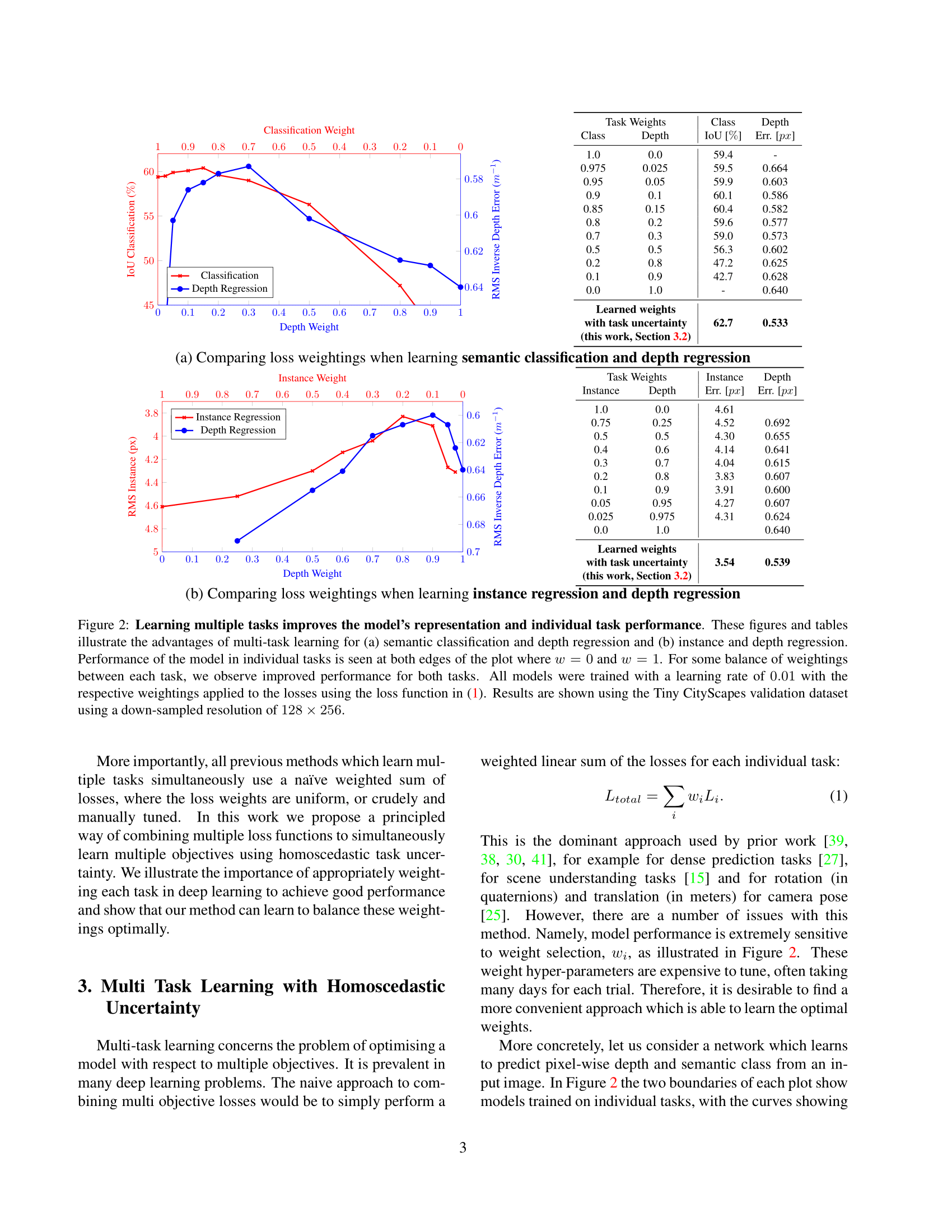
Multi-task learning concerns the problem of optimising a model with
respect to multiple objectives. The naive approach to combining multi
objective losses would be to simply perform a weighted linear sum of the
losses for each individual task:
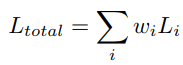
However, there are a number of
issues with this method. Namely, model performance is extremely
sensitive to weight selection, wi, as illustrated in Figure 2. These
weight hyper-parameters are expensive to tune, often taking many days
for each trial. Therefore, it is desirable to find a more convenient
approach which is able to learn the optimal weights
Mathematical Formulation
First the paper defines multi-task likelihoods:
- For regression
tasks, likelihood is defined as a Gaussian with mean given by the model
output with an observation noise scalar σ:
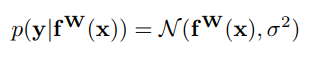
- For classification,
likelihood is defined as:
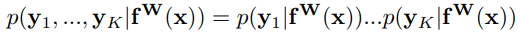
where:
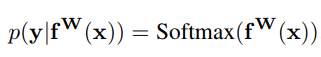
In maximum likelihood inference, we maximise the log likelihood of
the model. In regression for example:
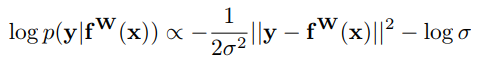
σ is the model’s observation
noise parameter - capturing how much noise we have in the outputs. We
then maximise the log likelihood with respect to the model parameters W
and observation noise parameter σ.
Assuming two tasks that follow a Gaussian distributions:
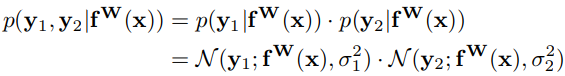
The loss will be:
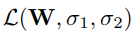

This means that W and σ are the learned
parameters of the network. W are the wights of the network while σ are
used to calculate the wights of each task loss and also to regularize
this task loss wight.
However, the extension to classification likelihoods is more
interesting. We adapt the classification likelihood to squash a scaled
version of the model output through a softmax function:
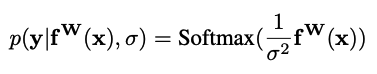
with a positive scalar σ. This can be
interpreted as a Boltzmann distribution (also called Gibbs distribution)
where the input is scaled by σ2 (often referred to as temperature). This
scalar is either fixed or can be learnt, where the parameter’s magnitude
determines how ‘uniform’ (flat) the discrete distribution is. This
relates to its uncertainty, as measured in entropy. The log likelihood
for this output can then be written as
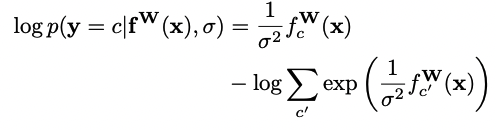
assume that a model’s multiple outputs are
composed of a continuous output y1 and a discrete output y2, modelled
with a Gaussian likelihood and a softmax likelihood, respectively. Like
before, the joint loss, L(W, σ1, σ2), is given as:
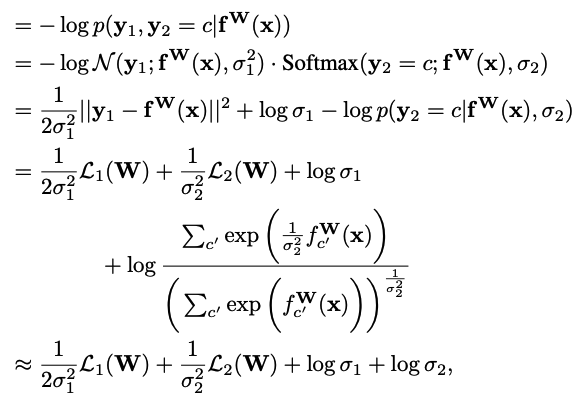
In
practice, we train the network to predict the log variance, s := log σ2.
This is because it is more numerically stable than regressing the
variance, σ2, as the loss avoids any division by zero. The exponential
mapping also allows us to regress unconstrained scalar values, where
exp(−s) is resolved to the positive domain giving valid values for
variance.
代码实现
1 | |
论文