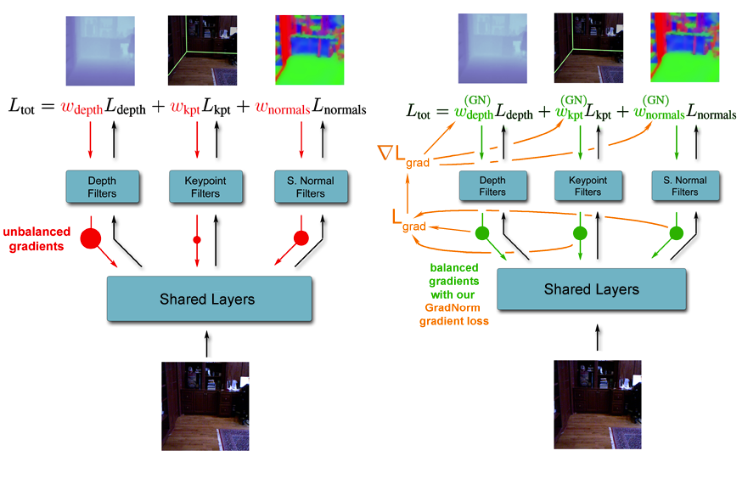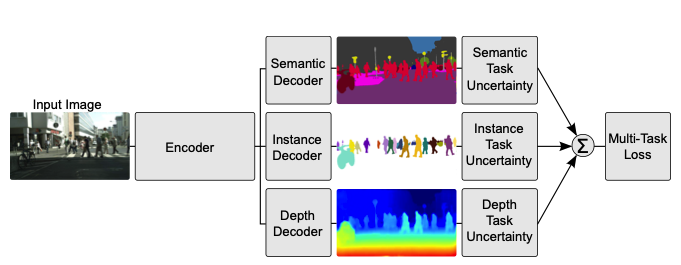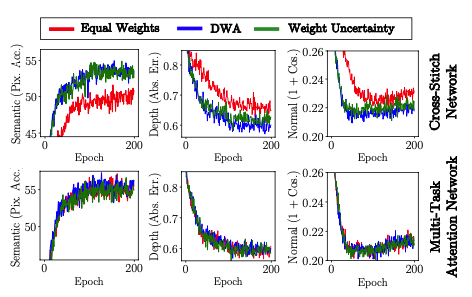
End-to-End Multi-Task Learning with Attention
代码实现 12345678910111213141516171819202122232425262728293031323334353637383940414243444546474849505152535455class LossesDWAModel(tf.keras.Model): def __init__(self, temperature=1, *args, **kwargs):